

Retrieval Augmented Generation
One of the most cost-effective, easy to implement, and lowest-risk path to higher performance for GenAI applications


Retrieval Augmented Generation (RAG) is an AI technique that enhances the quality of Large Language Model (LLM) responses by grounding them in external, verifiable knowledge sources. It combines the generative power of LLMs with the precision of information retrieval, leading to more accurate, up-to-date, and contextually relevant outputs.
Bridging the knowledge gap of LLMs
LLMs are trained on vast but static datasets, meaning their knowledge is frozen at the point of their last training. This can lead to outdated information, a lack of domain-specific knowledge, and a tendency to "hallucinate" or generate plausible but incorrect information. Retrieval Augmented Generation (RAG) has emerged as a powerful solution to address these challenges, significantly enhancing the reliability and accuracy of LLM-generated content. Since the information is grounded based on an existing knowledge source, this makes it very unlikely for an LLM to cook up some random information against a search query.
Core Idea
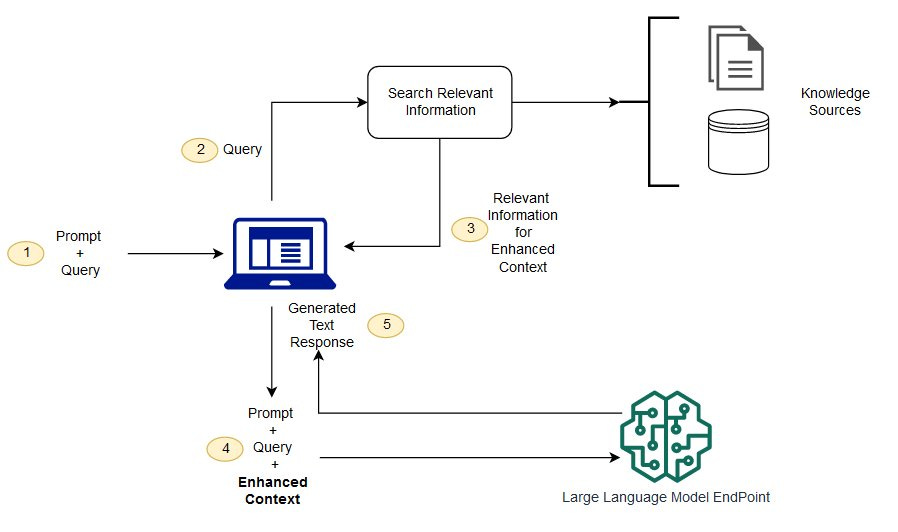
At its core, RAG is an architectural approach that combines the generative capabilities of LLMs with an external knowledge retrieval system. Instead of relying solely on the information embedded in its training data, a RAG system first fetches relevant information from a specified knowledge base (e.g., a collection of documents, a database, or an API) based on the user's query. This retrieved information is then provided as context to the LLM, which uses it to generate a more informed and accurate response.
Think of it like an open-book exam for an LLM. Rather than trying to recall information from memory (its training data), the LLM gets to consult relevant notes (the retrieved documents) before answering the question. This process grounds the LLM's response in factual, up-to-date, or domain-specific information.
The key benefits of RAG
Improved Accuracy and Reduced Hallucinations: By providing relevant, factual context, RAG significantly reduces the likelihood of LLMs generating incorrect or nonsensical information (hallucinations). The responses are grounded in the retrieved data.
Provide LLM, Access to Up-to-Date Information: LLMs inherently possess static knowledge. RAG allows them to access and utilize the latest information from external sources without needing to be retrained, which is a costly and time-consuming process.
Enhanced Domain-Specific Knowledge: RAG enables LLMs to provide expert-level responses in specific domains (e.g., medical, legal, finance) by connecting them to curated, domain-specific knowledge bases. This allows for tailored and accurate information delivery.
Increased Transparency and Trust: Because RAG systems retrieve information from specific sources, they can often cite these sources in their responses. This allows users to verify the information and builds trust in the system's outputs.
Cost-Effectiveness: Compared to fine-tuning an LLM with new data for every specific task or knowledge update, RAG is generally more cost-effective. Updating the external knowledge base is typically simpler and cheaper than retraining a massive language model.
Personalization: RAG can be used to personalize responses by retrieving information relevant to a specific user's context, history, or preferences.
Key Components

Knowledge base
This is the foundation of the "retrieval" aspect. It's the external corpus of information that the RAG system will draw upon to inform its responses. It can consist of a wide variety of data, including unstructured data like PDFs, Word docs, TXT files, articles, web pages, FAQs, internal wikis, semi structured like JSON files, CSV files with textual content etc.
The quality, relevance, and comprehensiveness of the knowledge base directly impact the accuracy and usefulness of the RAG system's outputs. If the information isn't in the knowledge base, the RAG system can't retrieve it.
The Data Preprocessing and Indexing Pipeline
This offline process prepares the knowledge base for efficient and effective retrieval. The key steps in this are
Data Loading: Ingesting the raw data from the specified sources.
Chunking: Breaking down large documents into smaller, semantically meaningful segments or "chunks." This is crucial because the LLMs have limited context window sizes and smaller chunks allow for more precise retrieval of relevant information. It’s important to note that chunking strategies can significantly impact retrieval performance.
Metadata Extraction: Optionally, extracting and associating metadata with each chunk (e.g., source document, creation date, author, keywords). This can be used for filtering or providing context during retrieval.
The Embedding Model
The embedding model is responsible for transforming text (both the document chunks from the knowledge base and the user's query) into numerical representations called vector embeddings. Typically, these are sophisticated neural network models, often based on Transformer architectures (e.g., BERT, Sentence-BERT, Ada from OpenAI, or open-source alternatives like those from Hugging Face).
An embedding model captures the semantic meaning of the text. Text segments with similar meanings will have vector embeddings that are close to each other in the high-dimensional vector space, while dissimilar texts will be further apart.
The quality of the embedding model is paramount. A good model will:
Accurately represent the semantics of the text.
Distinguish subtle differences in meaning.
Align well with the types of queries and documents the RAG system will handle.
Note: The same embedding model must be used for embedding the knowledge base documents and for embedding the user queries at runtime to ensure that the similarity comparisons are meaningful.
The Vector Database
Vector database is a specialized database designed to store, manage, and efficiently search through large quantities of vector embeddings. It has the following main functions
Storage: It stores the vector embeddings generated from the document chunks, often alongside the original text chunks themselves or a reference to them, and any associated metadata.
Indexing: It creates an index of these vectors to enable fast similarity searches. Common indexing techniques include Approximate Nearest Neighbor algorithms which trade off a small amount of accuracy for significant speed gains, especially with large datasets.
Similarity Search: When a user query (also converted to a vector embedding) is received, the vector database compares this query vector to the vectors in its index and retrieves the 'k' most similar vectors (and their corresponding text chunks). The similarity is typically measured using metrics like cosine similarity or Euclidean distance.
Some examples of popular vector databases are Pinecone, Weaviate, Milvus, Chroma, FAISS etc.
The Retriever Component
Retriever orchestrates the process of fetching relevant information from the vector database based on the user's query. The retriever performs the following steps
Takes the user's query.
Uses the embedding model to convert the query into a vector embedding.
Sends this query embedding to the vector database.
Receives the top-k most relevant document chunks (the "context") from the vector database.
May include logic for filtering results based on metadata, re-ranking retrieved chunks, or combining results from multiple retrieval strategies.
The retriever is the bridge between the user's need for information and the stored knowledge. Its efficiency and accuracy in finding the right context are critical.
The Large Language Model (LLM):
A LLM like GPT, Gemini etc serve as the generative engine of the RAG system. It takes the user's original query and the retrieved context and synthesizes them to produce a coherent, human-like answer. The LLM layer is responsible for
Prompt Augmentation: The original user query is combined with the retrieved context. This is often done by formatting a new, augmented prompt that instructs the LLM to use the provided context to answer the query. For example:
"Context: [retrieved document chunk 1] [retrieved document chunk 2] ... Question: [original user query] Answer based on the provided context:"Information Synthesis: The LLM processes this augmented prompt. Its pre-trained ability to understand language, reason, and generate text allows it to:
Understand the query in light of the new information.
Extract relevant facts from the context.
Synthesize these facts into a fluent and relevant answer.
Avoid relying solely on its internal, potentially outdated or generic knowledge.
Response Generation: Produces the final textual response for the user.
The LLM's capabilities in comprehension, reasoning, and generation determine the quality, naturalness, and usefulness of the final output. Its ability to perform "in-context learning" using the provided context effectively is key to RAG's success.
In summary, a RAG system is a multi-stage process where data is first processed and stored in a searchable vector format. Then, at query time, relevant information is retrieved, and finally, this retrieved information is used by an LLM to generate an informed and contextually grounded response (LLM + Orchestrator).
I’ve been building RAGs using various LLMs and frameworks, and you’d be surprised at how easy it is to build one. If you’d like to read more about Agentic AI and other aspects of modern computation, feel free to subscribe to the compute blog for free. With that, thank you so much for reading and I hope you have a wonderful day!