

What are orchestrators in data systems?
Everything you need to know about modern data pipeline orchestration


What are orchestrators?
Orchestrators are tools designed to manage, schedule, and monitor complex workflows in data pipelines and software systems. They allow developers to automate a sequence of tasks or workflows, define dependencies between tasks, and ensure that each task is executed in the right order, typically handling data processing, ETL (Extract, Transform, Load) operations, and other repetitive tasks.
Core Functions
Workflow Scheduling: Orchestrators schedule tasks to run at specific times or intervals, allowing for automating workflows. This is essential for pipelines that require regular updates, like daily data ingestion or processing tasks.
Dependency Management: Workflows often involve tasks that depend on the completion of other tasks. Orchestrators allow you to define these dependencies so that tasks are executed in the correct order.
Error Handling and Logging: Orchestrators track the success and failure of each task and offer logs for debugging. If a task fails, they can retry it or notify the appropriate team, ensuring that errors are caught and handled efficiently.
Parallelization and Scalability: Orchestrators can run multiple tasks in parallel if they are independent, which helps reduce the total time required for workflow execution. They also integrate with distributed computing resources, making them scalable as workload demands increase.
Monitoring and Alerting: They provide tools to monitor workflow execution in real time and can send alerts if tasks fail or if there are delays. This helps maintain reliability and uptime, especially for critical pipelines.
Benefits of Using Orchestrators in Software Systems:
Automation: By automating repetitive workflows, orchestrators save developers time and minimize manual errors.
Reliability & Resilience: The ability to handle dependencies and retry failed tasks ensures that workflows are resilient to interruptions.
Scalability: As workflows grow in complexity, orchestrators can scale to accommodate more tasks, dependencies, and larger volumes of data.
Better Collaboration and Visibility: Teams can easily visualize, monitor, and manage workflows, improving collaboration and transparency.
Popular orchestrators in the data engineering space
Apache Airflow
Apache Airflow allows you to define almost any workflow in Python code, no matter how complex. Because of its versatility, Airflow is used by companies all over the world for a variety of use cases.

Some of the main characteristics of airflow are
Python-Based DAGs: Workflows are defined as Directed Acyclic Graphs (DAGs) in Python, allowing for great flexibility and customization.
Dependency Management: Supports complex dependency handling to sequence tasks.
Extensibility: Integrates with many tools and services through a vast array of plugins and operators.
Strong UI for Monitoring and Control: Offers a user-friendly web interface for monitoring and managing workflows.
Apache airflow is best for Data engineering and ETL workflows where customization is critical.
Luigi

Luigi is a Python package that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization, handling failures, command line integration, and much more.
Some of the main characteristics of Luigi are
Dependency Resolution: Particularly strong at handling complex dependencies across a wide array of tasks.
Pipeline Simplicity: Ideal for simpler, sequential pipelines with many tasks but relatively straightforward logic.
Command-Line Interface: Workflow management and execution are command-line-driven, which suits developers comfortable in that environment.
Luigi is best for data pipeline automation with simpler task flows, typically used for ETL in data science or analytics tasks.
Prefect
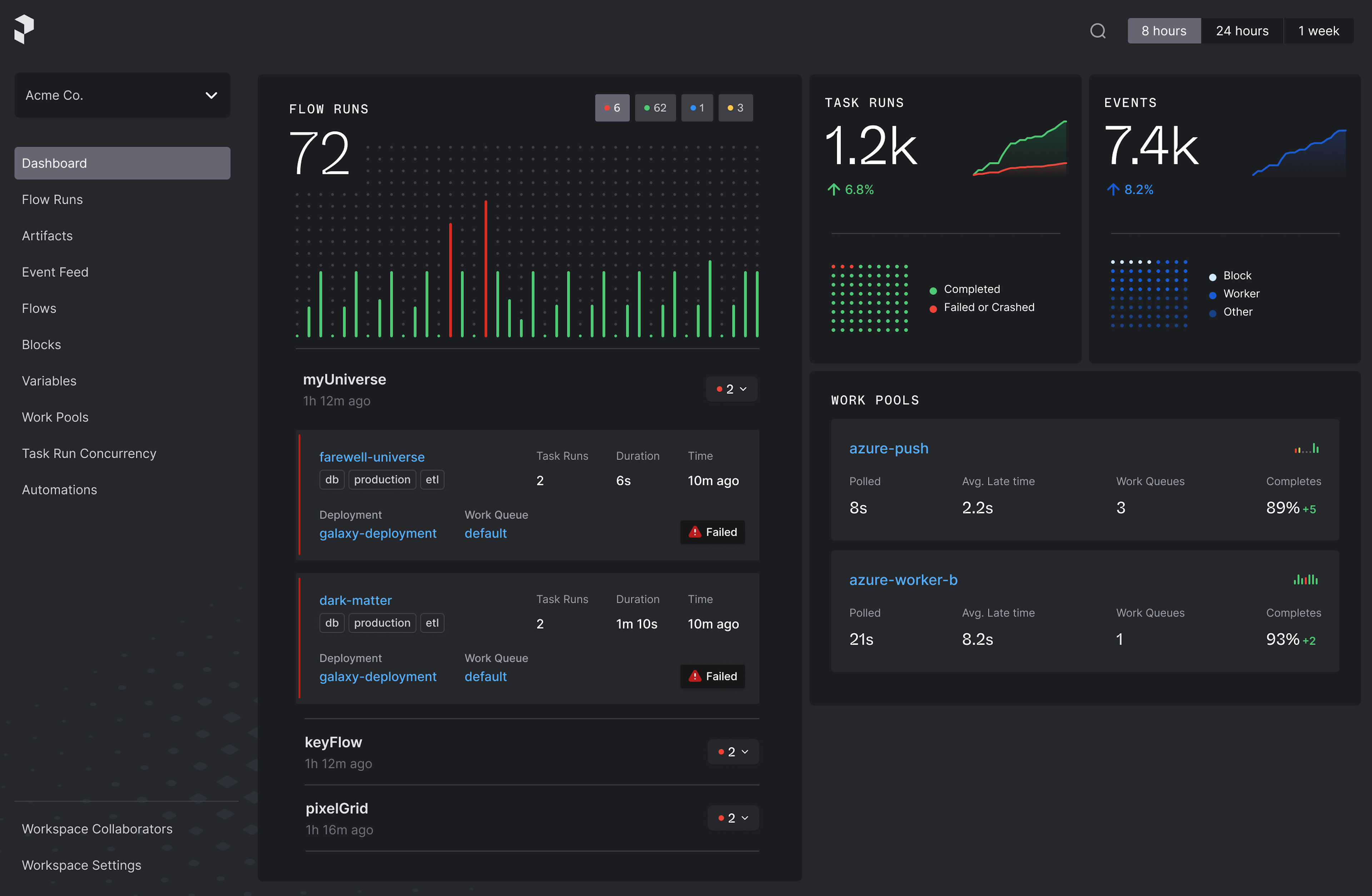
Prefect is one of the newer names in the market. It allows you to orchestrate your code with scheduling, automatic retries, and prioritized instant alerting, giving you full observability into your workflows. Of all the orchestrators in the list, Prefect is my favorite as the implementation is simply, really good!
Some of the main characteristics of prefect are
Pythonic and Flexible: Also Python-based like Airflow but with a focus on easy-to-use syntax and configuration.
Dynamic Task Mapping: Allows for dynamic task creation at runtime, which is beneficial for variable-length workflows.
Fault Tolerance and Resilience: Provides robust error handling, making it easy to rerun workflows from a failed task.
Hybrid Cloud Execution: Supports both cloud and local execution, allowing users to manage infrastructure more flexibly.
Prefect is best for scalable, resilient workflows where cloud integration and error handling are a high priority.
KubeFlow Pipelines

Kubeflow Pipelines (KFP) is a platform for building and deploying portable and scalable machine learning (ML) workflows using Docker containers.
Some of the main characteristics of kubeflow pipelines are
Kubernetes-Native: Designed for running on Kubernetes, making it ideal for containerized applications.
Machine Learning (ML) Focused: Specifically built to manage ML workflows, including model training, deployment, and monitoring.
Parameterization and Iteration: Great support for hyperparameter tuning, parameterized runs, and experiment tracking.
Integration with ML Tools: Works well with TensorFlow, PyTorch, and other popular ML frameworks.
Kubeflow pipelines are best for Orchestrating and automating ML workflows in Kubernetes environments.
Dagster
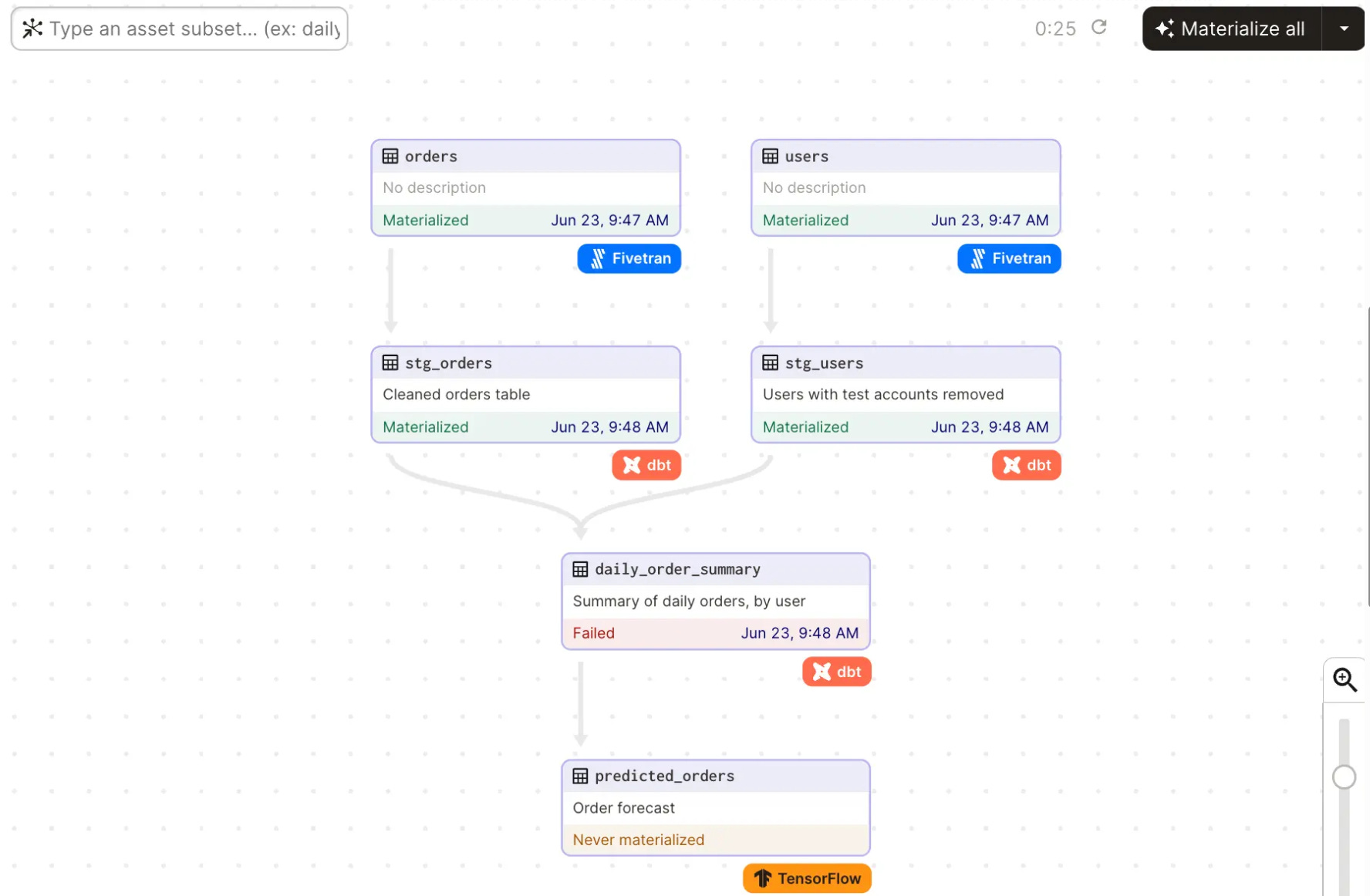
Dagster models pipelines in terms of the data assets they produce and consume, which, by default, brings order and observability to your data platform. Assets in Dagster can model data produced by any system, such as dbt models, Snowflake tables, or even CSV files.
Main characteristics of Dagster are
Type-Safe and Data-Driven: Incorporates type-safety and data validation, making it a popular choice for data-centric applications.
Modular and Component-Based: Allows users to manage individual tasks as reusable modules, simplifying complex workflows.
Strong Debugging and Testing Support: Provides tools for developing, testing, and debugging data pipelines.
Dagster is best for data-heavy workflows where data quality and validation are key requirements, especially in data engineering and analytics.
In future articles, we’ll dive deep into each of these and see how we can set these up fast and understand their fundamentals and intermediate concepts. If you’re interested in reading about them or similar topics, feel free to subscribe to my blog for free using the button below.
Thanks for reading! I hope you have a wonderful day!