

AI Agent tools
The tools that you should know about, while developing AI agents


With the recent launch of GPT-5, a few weeks ago, we’ve started to see a decline in the expansion of capabilities of Large Language Models. While the benchmarks associated with GPT-5 look promising, some industry experts think that the actual implementation seems a bit more focused on cutting down costs and increasing optimizations for running at scale, at OpenAI. The question at this stage in AI research is how much more capable, are LLMs going to get, and with the recent research by Apple on the illusion of thinking, and the more recent MIT study highlighting the zero return obtained by 95% of organizations using AI, the question around the ROI of AI agents is ever-more relevant. How can we derive the value with these LLMs that we’ve built, and assuming that the pace of gains in LLM capabilities is going to slow down, how can we build AI solutions that deliver impact early and using the existing capabilities of LLMs, instead of their future promise.
The way I like to think of AI agents is to think of the large language model as the brain, and the tools as it’s arms and legs. You can have a great brain, but if you store that brain in a jar, there’s not much that the brain will be able to do. In the AI industry, people understood this problem fairly early, and we now have a plethora of tools and techniques to give our AI brains, capabilities for them to make a difference. But as I interact with people about their understanding of Agents, I find that not many people are really aware of the scope of tools that are available for these LLM brains to utilize. And your AI agent’s chance of delivering impact and value, highly depends upon your ability to provide it with the right tooling. This is what we’ll focus on in this article.

There are 5 types of tools that we’ll talk about in this article
Code Interpreter
Function calling
File Search
Web Search
MCP Servers
Code Interpreter
This tool can write it’s own code to solve specific problems. This is a very powerful capability as the LLM is provided a sandbox environment where it can run its code and do things that LLMs are bad at - like arithmetic problems. Suppose you want a large language model to compute compound interest for you. The large language model by itself does not have a good capability to do this for you, because it’s a language model. It can attempt to do this using some prompting technique like chain-of-thought etc, but generally, LLMs struggle a lot with arithmetic computations.
However, if the LLM can write it’s own code and run it in its own sandboxed runtime, it can potentially find the answer to most arithmetic problems extremely easily. With libraries like numpy and pandas available in python, data analysis is generally just a couple of lines of code, which the LLM can write and with this tool, run. The LLM can also generate plots and images for you, essentially acting as a super efficient data analyst, and with this, covers its limitation of not being natively good at arithmetic.

Function calling
This tool can choose which function in your codebase to call, and provide you with the right arguments to be passed to that function. The large language models acts as the decision making authority, choosing for you, which function in your codebase to call, depending upon the context. This is extremely powerful as well. Your functions written in C#, Java, or any programming language for that matter, can be utilized this way, and that is the point.
Traditional programming tells us what to do based on conditional statements like if-else statements. Machine learning solves specific problems after some kind of training - supervised or unsupervised. This is different as the LLMs come ready, out of the box with this functionality, and you don’t really need to change your programming stack to enable these capabilities. This is why, function calling has such a high potential of delivering value and remains one of the most impressive tools for modern agent development.
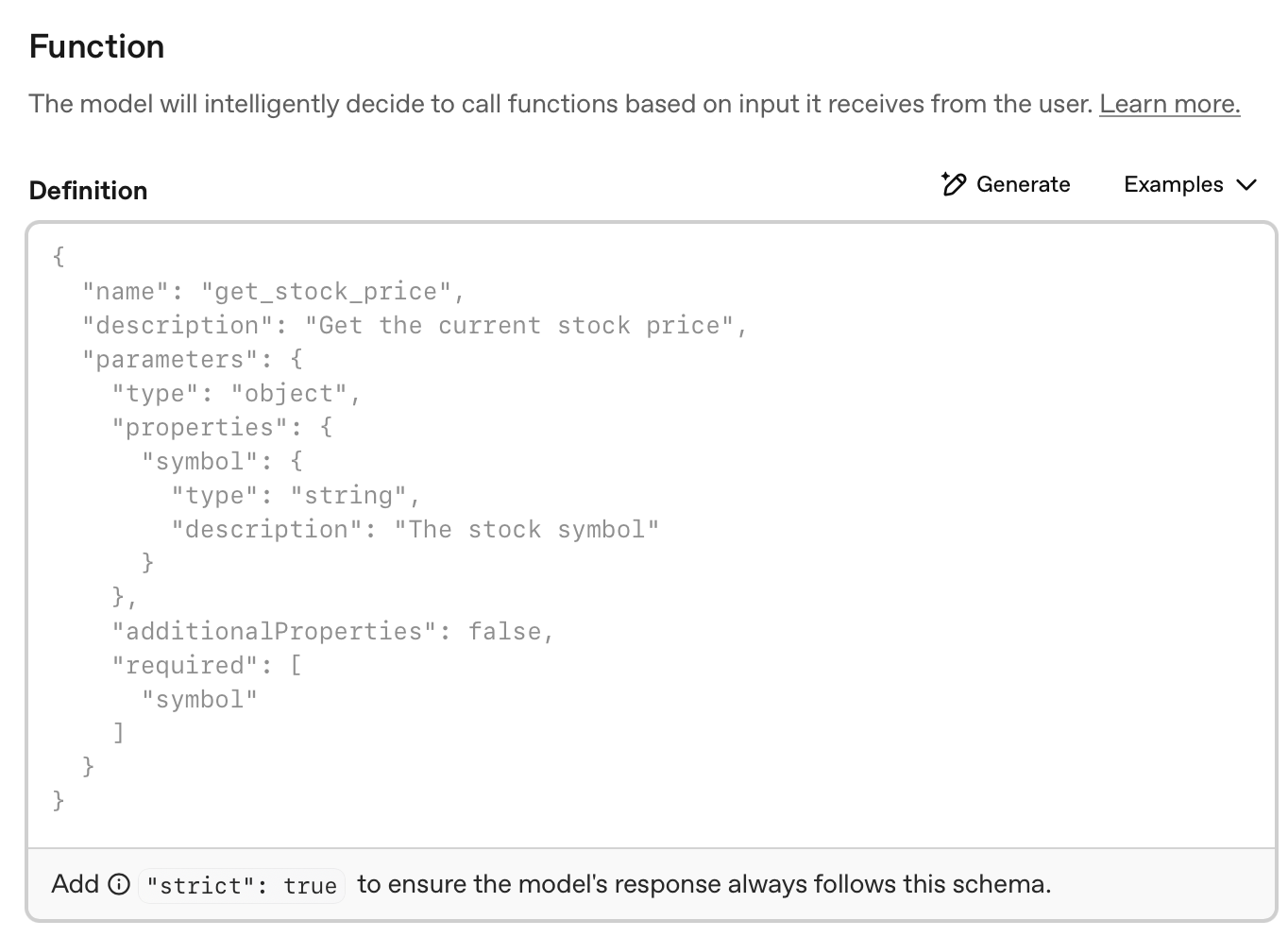
File Search
File search tool basically acts like a RAG - Retrieval Augmented Generation system. One of the most popular uses of LLMs is in RAG systems. And building these RAGs have never been simpler as they now essentially come as just another tool for LLMs to use, known as the file search tool. You can upload your own data in vector databases by uploading your own files like PDFs, word documents etc. This information is then stored in a vector database, fetched back by the retriever and curated by the LLM. RAGs used to be messy to build at one point of time, but the modern AI development landscape has made building RAG as simple as adding the file search tool to your LLM capabilities.
You can read more about RAGs over here at my article on RAG.
Web Search
All large language models today, have a cutoff date, on which their training dataset was cut-off. We solve the problem of giving the right context to an LLM through file search tool or an RAG, but what if we need something even more recent than what our RAG can offer. Also if we do not have information in our vector database, the LLM can use the web search functionality to figure out the right information it needs to make a decision and act on it. Web search allows a LLM to have access to a search engine the same way you and I run web searches. This addresses the cutoff date problem for LLMs, and makes them capable of knowing what is happening today, right now through search capabilities.
MCP Servers
The most recent, standard and industry accepted way of sharing information and context with LLMs is Model Context Protocol - MCP. It came out as a result of solving the frustrations seen at Anthropic (the company behind Claude LLM), while integrating LLMs with various other programs. It’s going to be a year since the inception of MCP and its safe to say that there’s very wide adoption of MCP across the industry. And for good reason, MCP solves the burning question - How to design AI systems such that they’re extensible, maintaining and discoverable. This means that sharing information from APIs, static files, blob storages, non-relational databases etc can be done in a standard way. MCP also defines server primitives that all servers can follow so that the users (MCP clients) can discover capabilities smartly. To learn about MCP more you can read my article on MCP in detail here.
When you put this together, you get something that looks like this diagram that I put together, below

This sums up the important pieces of tooling that enables AI agents to unlock capabilities never seen before in software engineering. These tools are the main reasons behind the automation capabilities of LLMs. Modern Agentic development hence, isn’t limited by the progress that we’re making on LLMs. We’re also making significant progress in tooling and as we make it easier and easier for these AI brains to use various types of tools, we should start seeing automation capabilities never seen before.